Supported Providers
A single Provider enum eliminates branching by vendor; mix local and cloud
(e.g. Ollama + OpenAI) effortlessly.
One API client, multiple providers: reliable streaming, function calls, reasoning models, and observability — with <1ms overhead.
Dual-licensed MIT / Apache-2.0 · Production-grade abstractions · Vendor neutral
One abstraction spans OpenAI, Groq, Anthropic, Gemini, Mistral, Cohere, etc.
Easy image and audio content creation with `Content::from_image_file()` and `Content::from_audio_file()`.
Standard incremental deltas; hides raw SSE differences.
Built-in support for Groq Qwen, DeepSeek R1, and other reasoning models with structured output.
Retries, timeout, error typing, proxy control, connection pooling.
Performance / cost / health / weighted routing out of the box.
Adds ~0.6–0.9ms per request (transparent methodology).
Scale from quick_chat to custom transports & metrics gradually.
ai-lib-pro provides advanced routing, observability, security, and cost management.
Add the dependency, then use the unified API to call any supported provider immediately.
[dependencies]
ai-lib = "0.3.4"
tokio = { version = "1", features = ["full"] }
futures = "0.3"use ai_lib::prelude::*;
#[tokio::main]
async fn main() -> Result<(), AiLibError> {
let client = AiClient::new(Provider::Groq)?;
let req = ChatCompletionRequest::new(
client.default_chat_model(),
vec![Message {
role: Role::User,
content: Content::new_text("Hello, world!"),
function_call: None,
}]
);
let resp = client.chat_completion(req).await?;
println!("Answer: {}", resp.choices[0].message.content.as_text());
Ok(())
}# Set API keys
export GROQ_API_KEY=your_groq_api_key
export OPENAI_API_KEY=your_openai_api_key
export ANTHROPIC_API_KEY=your_anthropic_api_key
# Proxy configuration (optional)
export AI_PROXY_URL=http://proxy.example.com:8080use ai_lib::prelude::*;
// Image content from file
let image_content = Content::from_image_file("path/to/image.png");
// Audio content from file
let audio_content = Content::from_audio_file("path/to/audio.mp3");
// Mixed content message
let messages = vec![
Message {
role: Role::User,
content: Content::new_text("Analyze this image"),
function_call: None,
},
Message {
role: Role::User,
content: image_content,
function_call: None,
},
];use futures::StreamExt;
let mut stream = client.chat_completion_stream(req).await?;
while let Some(chunk) = stream.next().await {
let c = chunk?;
if let Some(delta) = c.choices[0].delta.content.clone() {
print!("{delta}");
}
}
A single Provider enum eliminates branching by vendor; mix local and cloud
(e.g. Ollama + OpenAI) effortlessly.
The following metrics refer to SDK layer overhead only (excludes remote model latency). See repository README for full methodology. Always benchmark with your workload.
Note: Real-world throughput constrained by provider rate limits & network. Figures are indicative, not guarantees.
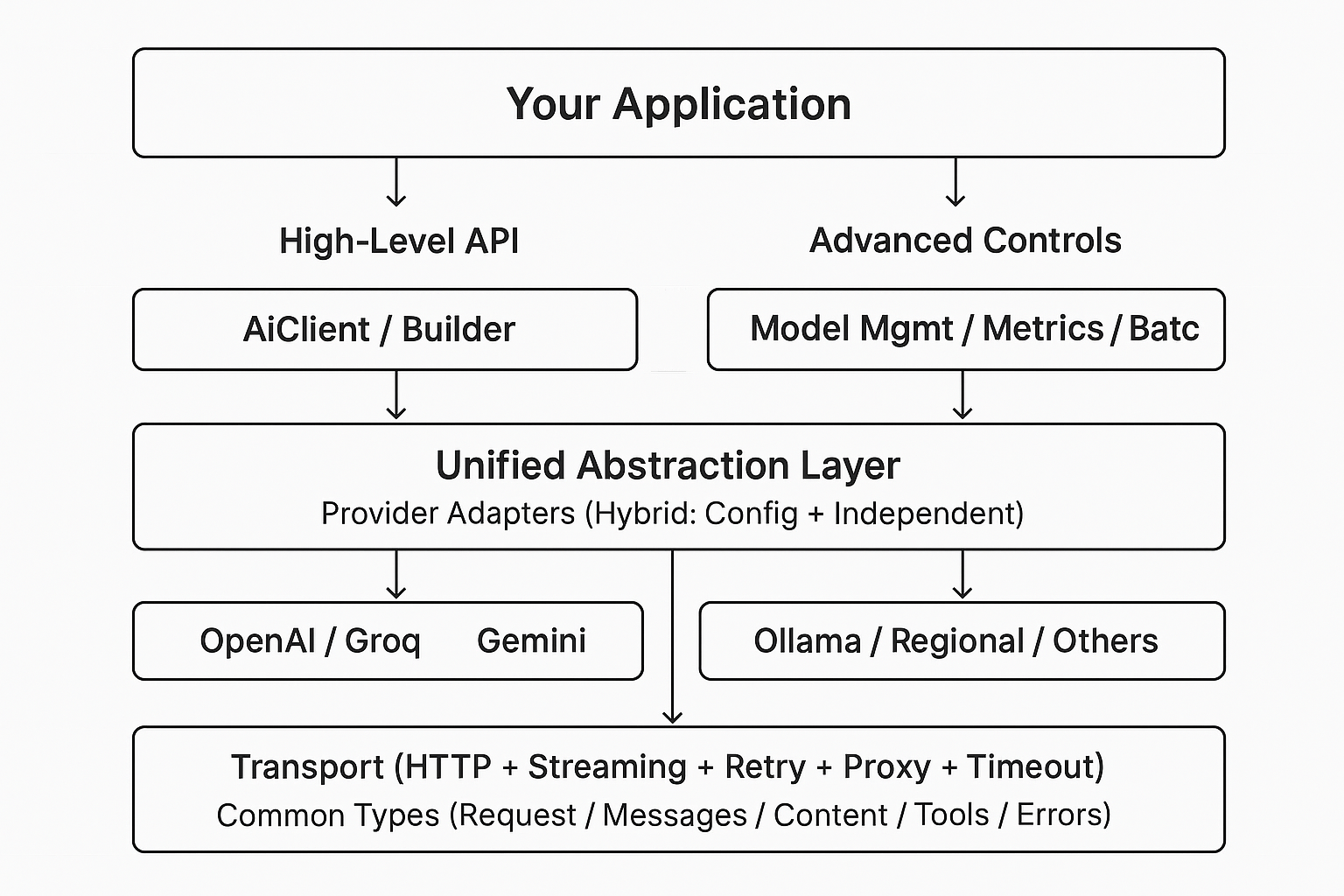
Layered design: App → High-level API → Unified abstraction → Provider adapters → Transport (HTTP/stream + reliability) → Common types.
We welcome enterprise inquiries for demos and engagements. Click below to contact us.